Logistic regression in python using the famous Titanic data set.
Author
John Robin Inston
Published
May 13, 2026
Modified
May 13, 2026
ImportantLearning Objectives
Define the logistic regression model.
Implement logistic regression in python using the famous Titanic classification data set.
Libraries and Styling
# Librariesimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom scipy.stats import norm, binomfrom scipy.special import expit # the logistic (sigmoid) functionimport statsmodels.formula.api as smfimport statsmodels.api as smfrom statsmodels.stats.anova import anova_lmfrom sklearn.metrics import ( confusion_matrix, ConfusionMatrixDisplay, roc_curve, roc_auc_score)# Figure stylingsns.set_style('whitegrid')sns.set_palette('Set2')
Logistic Regression
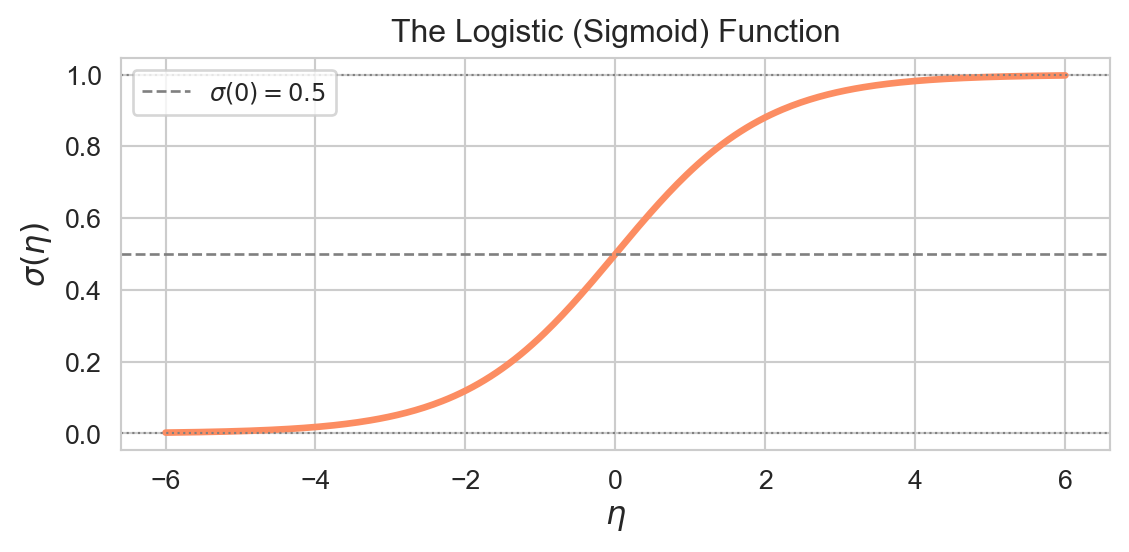
Logistic regression is the GLM for a binary response\(Y_i \in \{0,1\}\). It arises naturally in settings like: did a patient recover? did a loan default? is a species present at a site?
We assume \(Y_i \mid \mathbf{x}_i \sim \text{Bernoulli}(\pi_i)\) and model the log-odds (logit) of \(\pi_i\) as a linear function of the predictors:
Non-linear; depends on the values of all predictors
If \(\beta_j = 0.5\), then \(e^{0.5} \approx 1.65\): a one-unit increase in \(X_j\)multiplies the odds by \(1.65\). Odds ratios are multiplicative, not additive. If \(\beta_j < 0\), the odds decrease with \(X_j\).
The log-likelihood (also called binary cross-entropy) is:
A pseudo-\(R^2\) is often computed as McFadden’s \(R^2 = 1 - D/D_0\).
Application: Titanic Survival
We illustrate logistic regression on Titanic passenger data — a classic binary classification problem where \(Y = 1\) indicates survival, with predictors including class, sex, age, and fare.
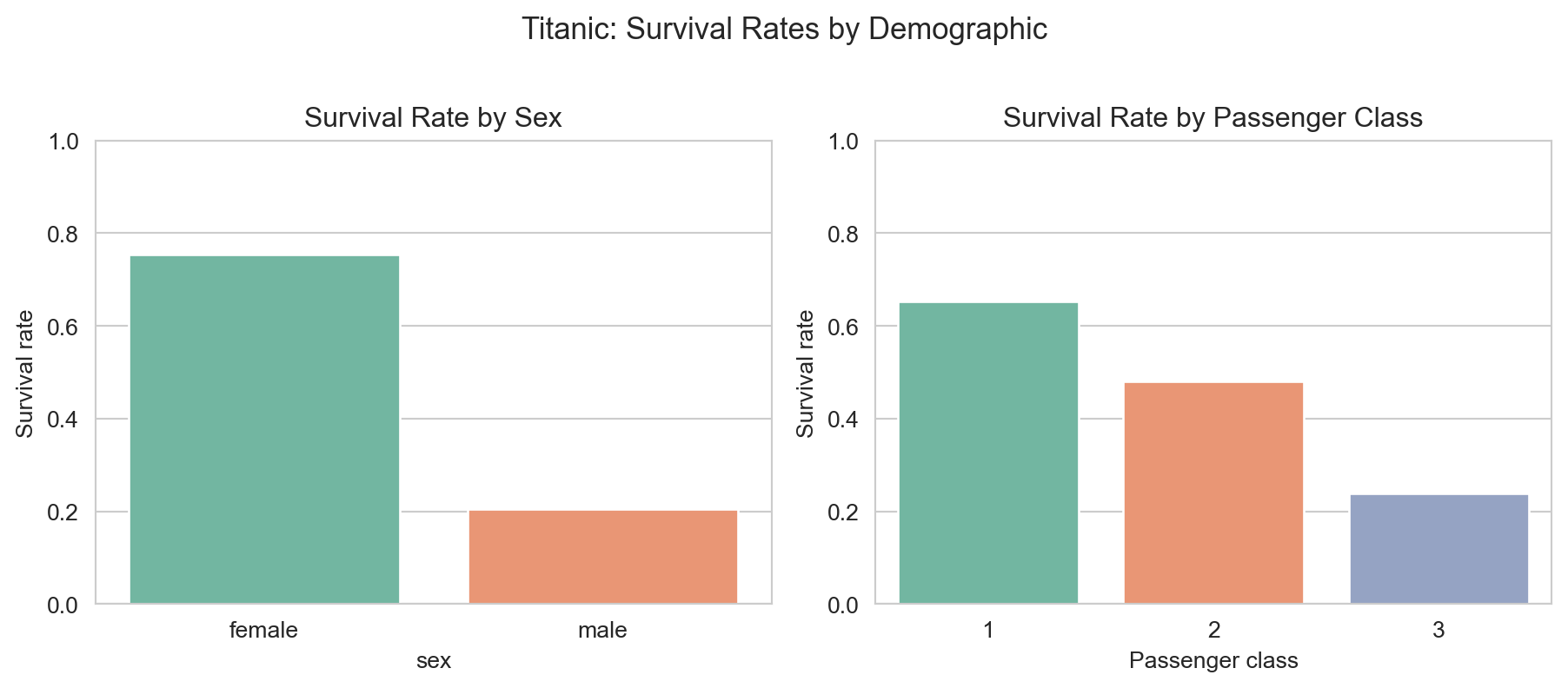
Survival rates by sex and passenger class. Women and first-class passengers had substantially higher survival rates.
KDE Plot Code
fig, ax = plt.subplots(figsize=(9, 4))for label, grp in titanic.groupby('survived'): sns.kdeplot(grp['age'], ax=ax, fill=True, alpha=0.4, label='Survived'if label ==1else'Did not survive')ax.set_xlabel('Age (years)')ax.set_ylabel('Density')ax.set_title('Age Distribution by Survival Outcome')ax.legend()plt.tight_layout(); plt.show()
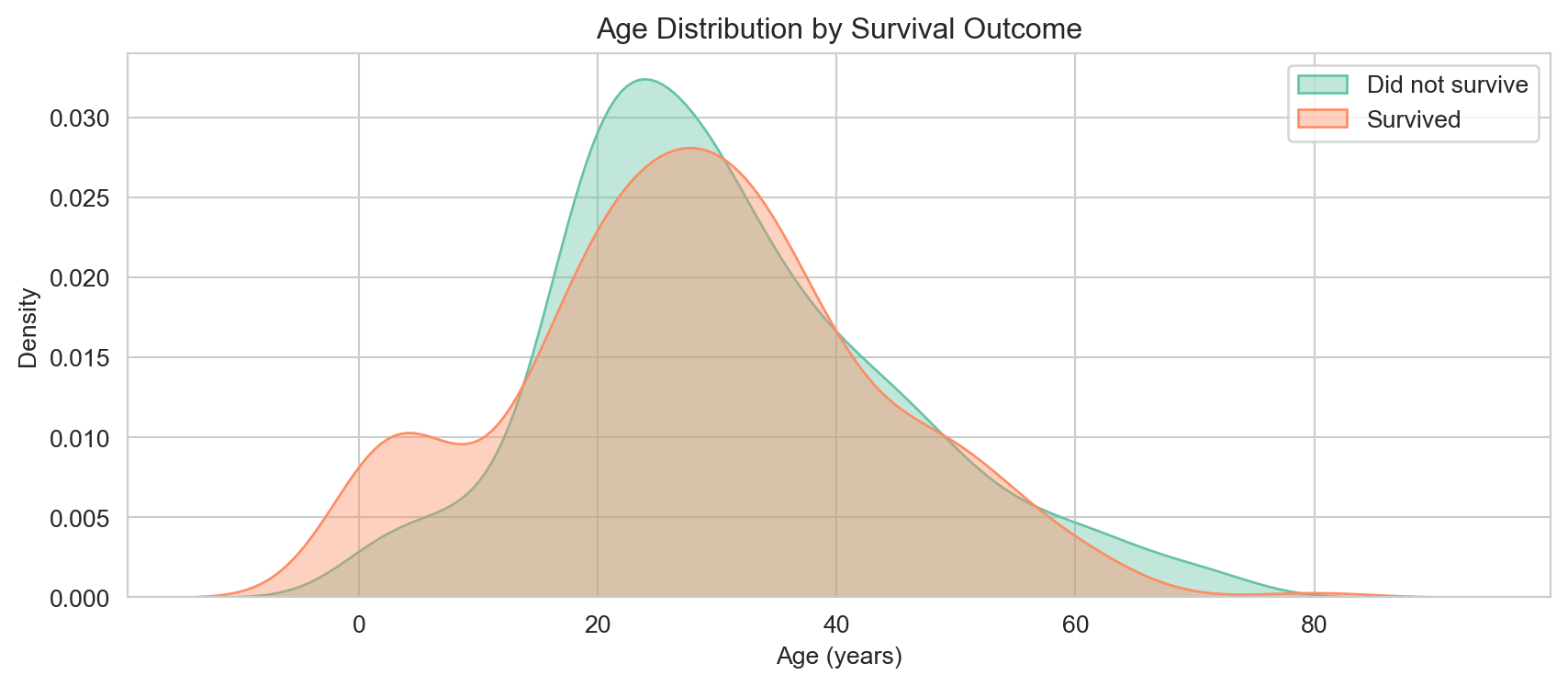
Age distributions for survivors and non-survivors. Children show a somewhat higher survival rate, consistent with the ‘women and children first’ policy.
We fit the model using smf.logit(), which uses the same formula syntax as smf.ols(). Categorical variables are automatically dummy-coded with C(...).
Standard errors and tests are based on the Wald statistic \(z = \hat{\beta}_j / \widehat{\text{SE}}(\hat{\beta}_j) \approx \mathcal{N}(0,1)\), a large-sample result from maximum likelihood theory.
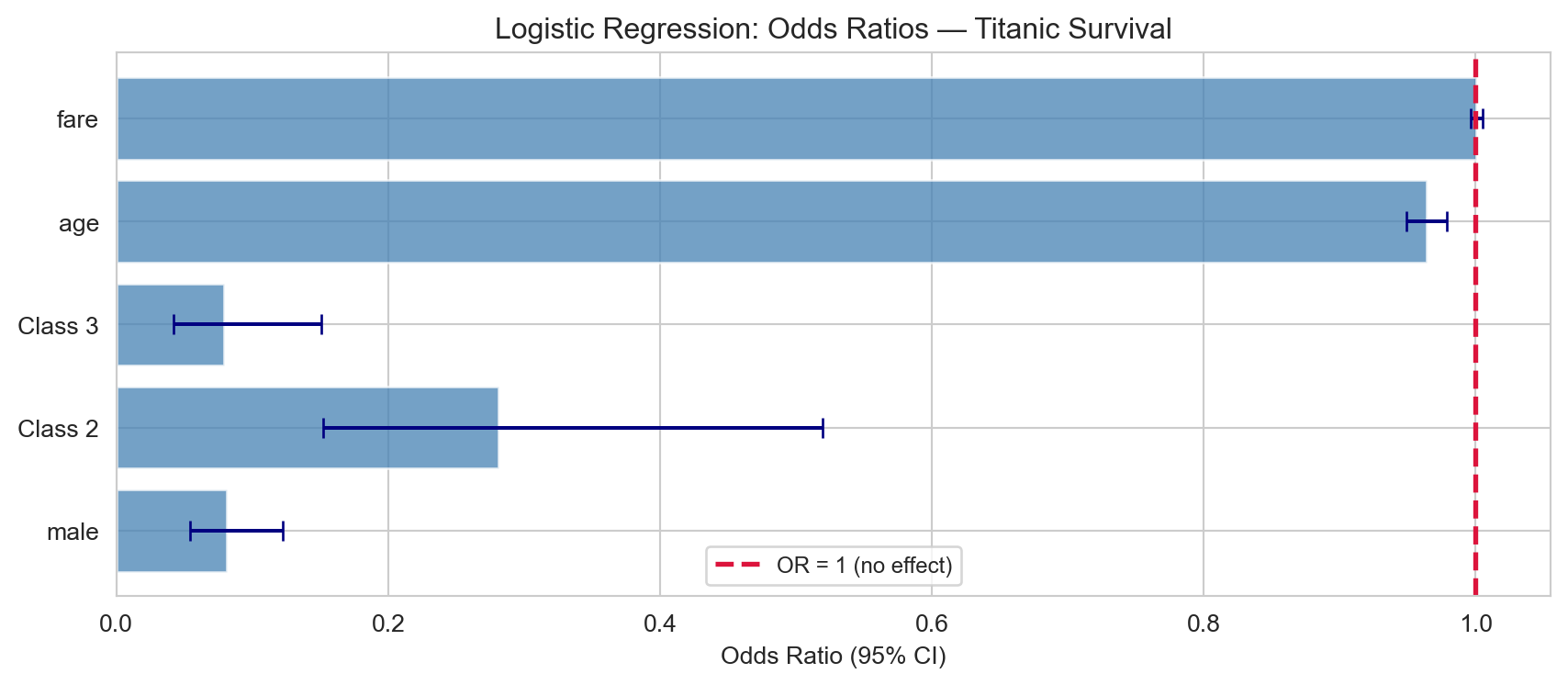
Odds ratios with 95% confidence intervals for the Titanic logistic regression. An odds ratio > 1 means increased odds of survival; < 1 means decreased odds.
We can predict probabilities for individual passengers using logit1.predict(). The coefficient table lives on the log-odds scale, but for communication we usually want probabilities:
newdata = pd.DataFrame({'sex': ['female', 'male'],'age': [30, 30],'pclass': [1, 3],'fare': [50, 10]})probs = logit1.predict(newdata)for i, row in newdata.iterrows():print(f" {row['sex']:6s}, age {row['age']}, class {row['pclass']}, "f"fare {row['fare']:.0f}: P(survive) = {probs[i]:.3f}")
female, age 30, class 1, fare 50: P(survive) = 0.933
male , age 30, class 3, fare 10: P(survive) = 0.081
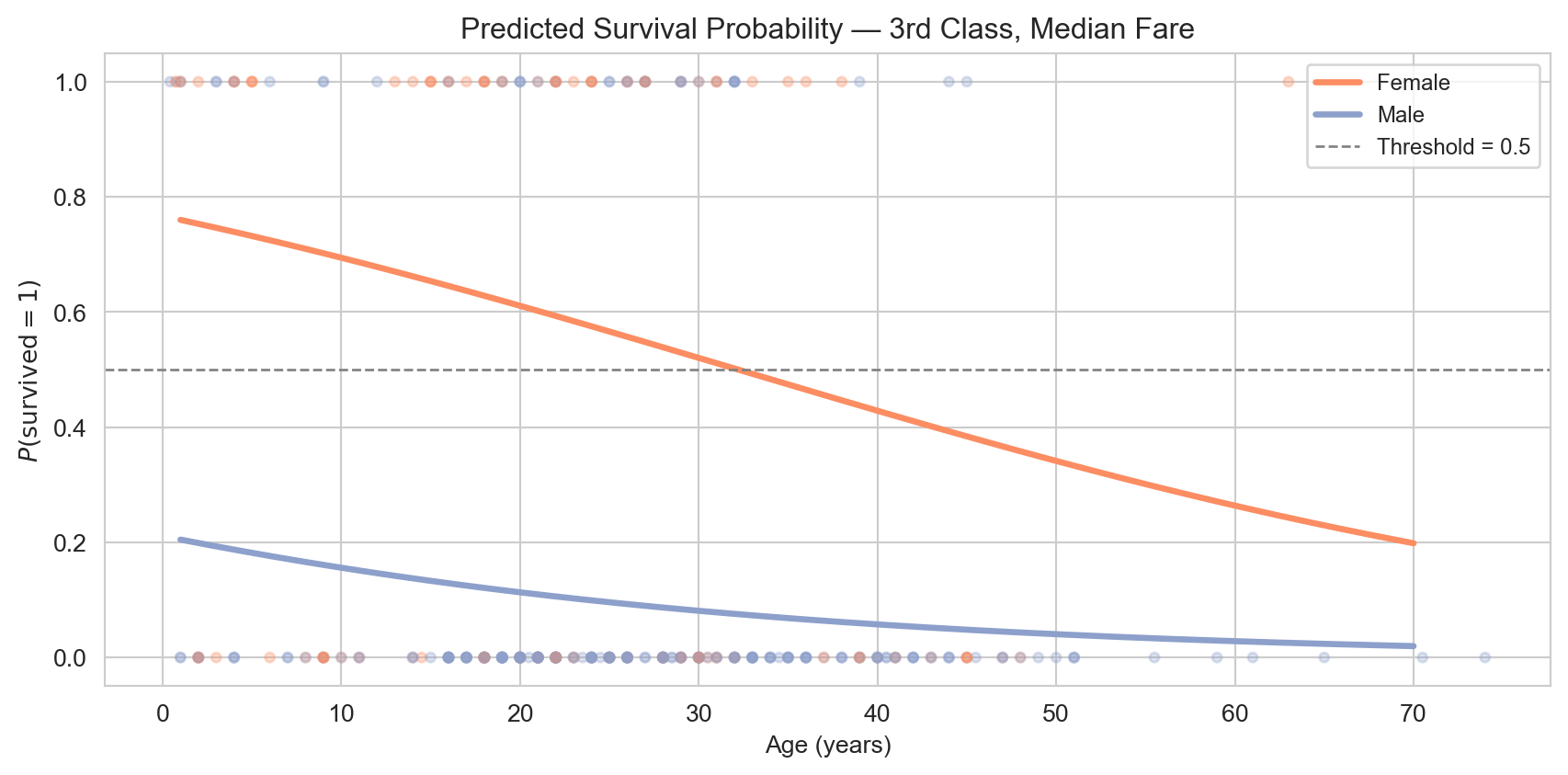
A 30-year-old female in first class has a high predicted survival probability; a 30-year-old male in third class has a much lower one — consistent with the historical record.
Predicted survival probability as a function of age, stratified by sex, for a third-class passenger with median fare. The logistic curve is clearly visible.
Classification Performance
ImportantIn-sample evaluation
The classification metrics below are computed on the same data used to fit the model, giving an optimistic picture of predictive performance. In a prediction-focused workflow you would split data into training and test sets before reporting these metrics. Here our primary goal is inference — understanding which predictors are associated with survival — and the classification metrics illustrate how a fitted logistic regression translates into a classifier.
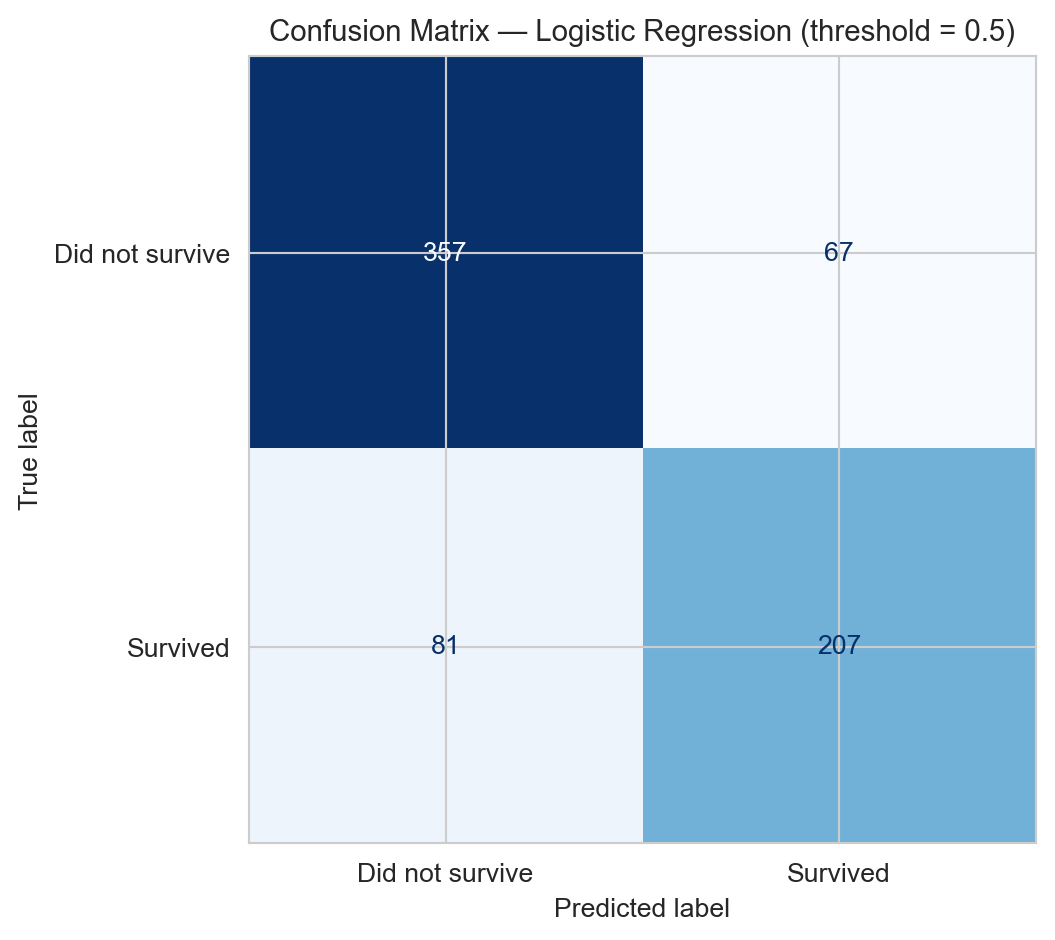
We classify \(\hat{Y}_i = 1\) if \(\hat{\pi}_i > 0.5\) and summarise performance with the confusion matrix and ROC curve.
Confusion matrix for the logistic regression model at threshold 0.5 (in-sample).
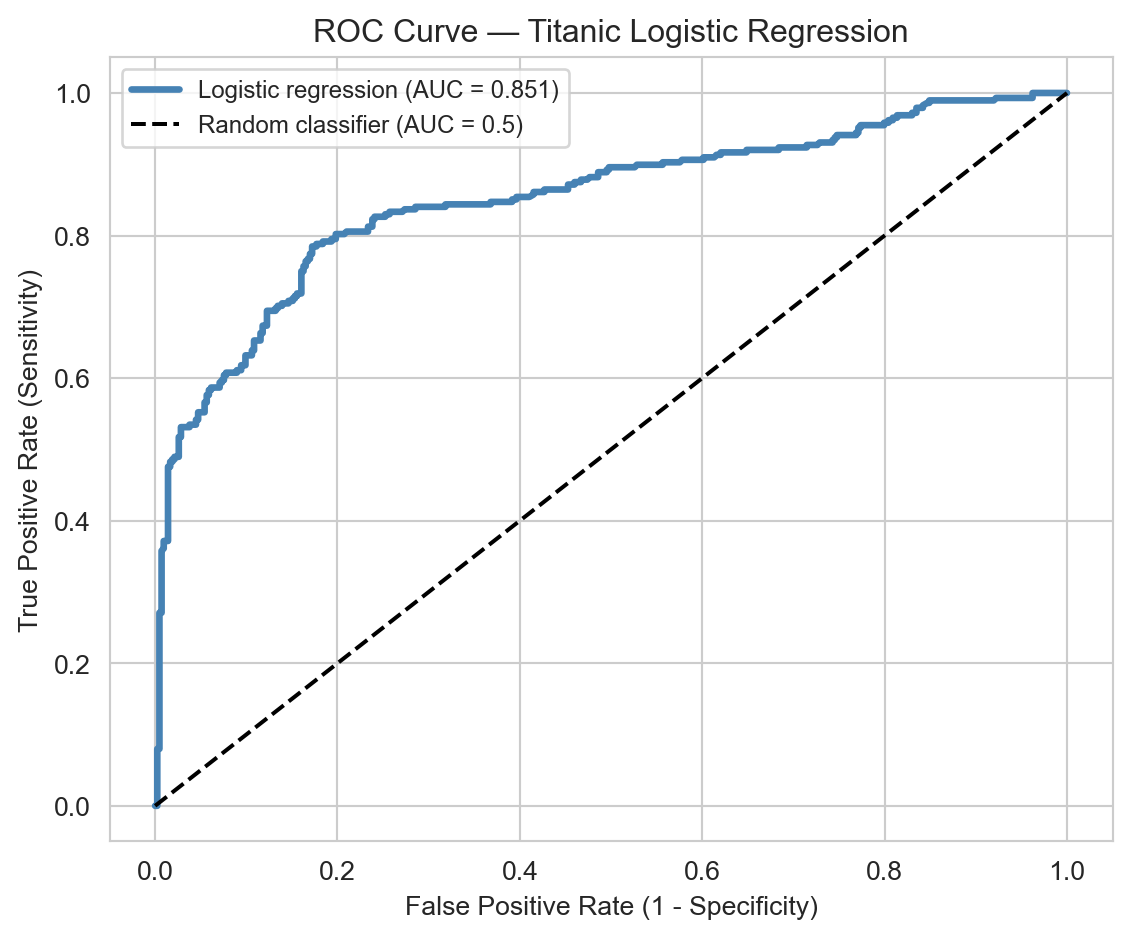
The ROC curve plots the true positive rate (sensitivity) against the false positive rate (1 - specificity) as the threshold varies from 1 to 0. The AUC (area under the ROC curve) measures overall discriminative ability: AUC = 1 is perfect; AUC = 0.5 is a random classifier.
ROC curve for the logistic regression model (in-sample). AUC substantially above 0.5 indicates good discriminative power.
We can test whether adding embark_town improves the model using the LRT: