Lecture 3: Sampling, Missingness, and Bias
PSTAT100: Data Science - Concepts and Analysis

University of California, Santa Barbara
July 13, 2026
Sampling Terminology
Here we’ll introduce standard statistical terminology to describe data collection.
Populations and Samples
- All data are collected somehow.
- A sampling design is a way of selecting observational units for measurement.
- It can be construed as a particular relationship between:
- a population (all entities of interest);
- a sampling frame (all entities that are possible to measure); and
- a sample (a specific collection of entities).

Population
Remember Observational Units
- Last week, we introduced the terminology observational unit to mean a certain (usually physical) entity measured for a study.
- Using this terminology, datasets consist of observations made on observational units.
- All data are data on some kind of thing, such as countries, species, locations, etc.
Populations
A statistical population is the collection of all units of interest. For example:
- All countries (GDP data).
- All mammal species (Allison 1976).
- All babies born in the US (babynames data).

Sampling Frame
Unmeasurable Units
- There are usually some units in a population that can’t be measured due to practical constraints
- Example: many adult U.S. residents don’t have phones or addresses.
Sampling Frame
- For this reason, it is useful to introduce the concept of a sampling frame, which refers to the collection of all units in a population that can be observed for a study.
- Some examples might be:
- All countries reporting economic output between 1961 and 2019.
- All nonendagered mammals that die of natural causes in monitored areas.
- All babies with birth certificates from U.S. hospitals born between 1990 and 2018.

Sample
Sample of Measurable Units
- Finally, it’s rarely feasible to measure every observable unit due to limited data collection resources
- States don’t have the time or money to call every phone number every year.
- A sample is a collection of units in the sampling frame actually selected for study. For instance:
- 234 countries;
- 62 mammal species;
- 13,684,689 babies born in CA;

Sampling Scenarios: Population Census
Perhaps the simplest scenario is a population census, where the entire population is observed. In this case:
\[S = F = P\]

Population Census.
From a census, all properties of the population are definitevely known.
- No need to model census data!
Sampling Scenarios: Simple Random Sample
The statistical gold standard is the simple random sample (SRS) in which units are selected at random from the population. In this case:
\[S \subset F = P\]

Simple Random Sample.
From a SRS, sample properties are reflective of population properties.
- Can safely extrapolate from the sample to the population.
Sampling Scenarios: Typical Sample
More common in practice is a SRS from a sampling frame that overlaps with the population but does not cover the population. In this case:
\[S \subset F \quad\text{and}\quad F \cap P \neq \emptyset\]

Typical Sample.
In this scenario, sample properties are reflective of the frame.
- Can extrapolate to a subpopulation, but not the full population.
Sampling scenarios: administrative data
Also common is administrative data in which all units are selected from a convenient frame that partly covers the population. In this case:
\[S = F \quad\text{and}\quad F\cap P \neq \emptyset\]

Administrative Data.
Administrative data are singular; they do not represent any broader group.
- No reliable extrapolation is possible.
Data quality
Making Judgements
- It’s easy to fall into value judgements about a dataset based on scope of inference and bias.
- But there’s nothing inherently better or worse about the scenarios we’ve considered.
- Our goal in all this is to create a framework for understanding the limitations of a given dataset so that we can make pragmatic choices about how to use it that align with the information it has to offer.
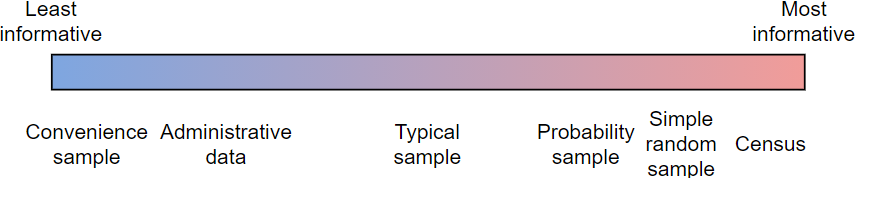
It may help to map the scenarios we’ve considered onto an ‘informativeness’ spectrum:
Missing Data Fixes - Mean Imputation
Perils of Mean Imputation
Imputation is the process of replacing missing values with estimated values, typically statistical estimates.
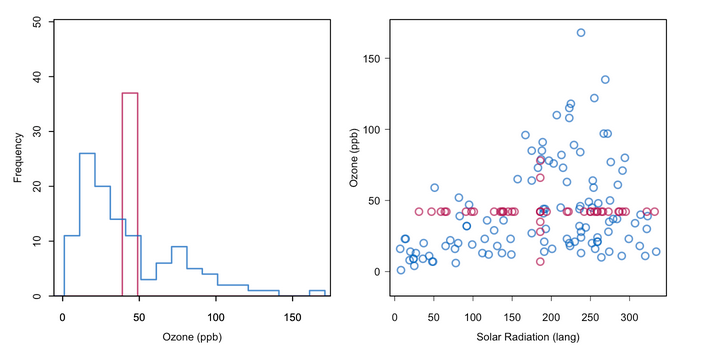
Mean Imputation
- Imputing too many missing values distorts the distribution of sample values.*
Miller Case - Survey schematic
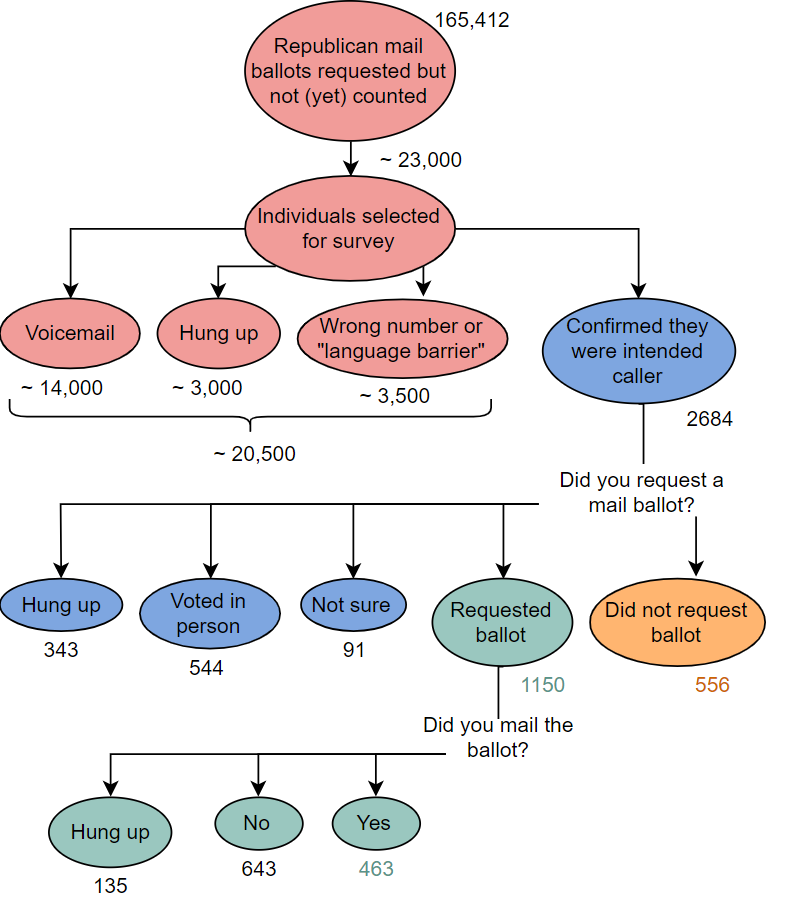
Miller Survey Schematic