| Breed | Age (Years) | Weight (kg) | Color | Gender | |
|---|---|---|---|---|---|
| 0 | Russian Blue | 19 | 7 | Tortoiseshell | Female |
| 1 | Norwegian Forest | 19 | 9 | Tortoiseshell | Female |
| 2 | Chartreux | 3 | 3 | Brown | Female |
| 3 | Persian | 13 | 6 | Sable | Female |
| 4 | Ragdoll | 10 | 8 | Tabby | Male |
Lecture 1: Data Science Fundamentals
PSTAT100 Data Science Concepts and Analysis
John Inston 
University of California, Santa Barbara
July 13, 2026
👋 Introduction
Welcome to PSTAT100 Data Science Concepts and Analysis! 🎉
🤝 About Me
- My name is John Inston.
- Pronouns: I use he/him/his pronouns.
- I am a 4th year PhD candidate 👴 in the Department of Statistics and Applied Probability.
- My research interests include stochastic games 🎲 and numerical optimization 💻.

Office Hours
🏢 OH: South Hall 5431T R 1PM to 3PM.
👩🏫 Teaching Staff
I am being assisted this term by the following wonderful teaching assistants:
Lauren Hughes
- Pronouns: she/her/hers
- ✉️ Email: laurenhughes@ucsb.edu
- 🏢 OH: TBD.
Yuting Ma
- Pronouns: she/her/hers
- ✉️ Email: yutingma@ucsb.edu
- 🏢 OH: TBD.
Zhuojun Lyu
- Pronouns: she/her/hers
- ✉️ Email: zhuojun@ucsb.edu
- 🏢 OH: TBD.



❗ Due to space availability section switching must be confirmed in advance with your TA.
💪 Python Bootcamp
What about if I am not familiar with Python? 🤔
![]()
When and Where?
I will be hosting a Python Bootcamp this Thursday from 1:00pm to 3:00pm in South Hall 5421.
❗ Attendance is optional!
Who is this for?
- Encouraged for anybody who is unfamiliar with Python or needs a refresher.
- Focus will be on IDE setup, basic functionality and document creation.
📊 Data Science
What is Data Science?
Let’s see what Claude thinks:

Fundamental Aims
Simply put…
Data science is the practice of using data to extract insights and knowledge. 👍
How does it work?
- Data science is an interdisciplinary field, requiring:
- Statistics
- Mathematics
- Computer science
- Domain knowledge
- Required to manage and interpret large, complicated data sets.

🤔 Notice that these disciplines loosely correspond to the prerequisites for this course.
Data Science Disciplines
Intersection of the Disciplines
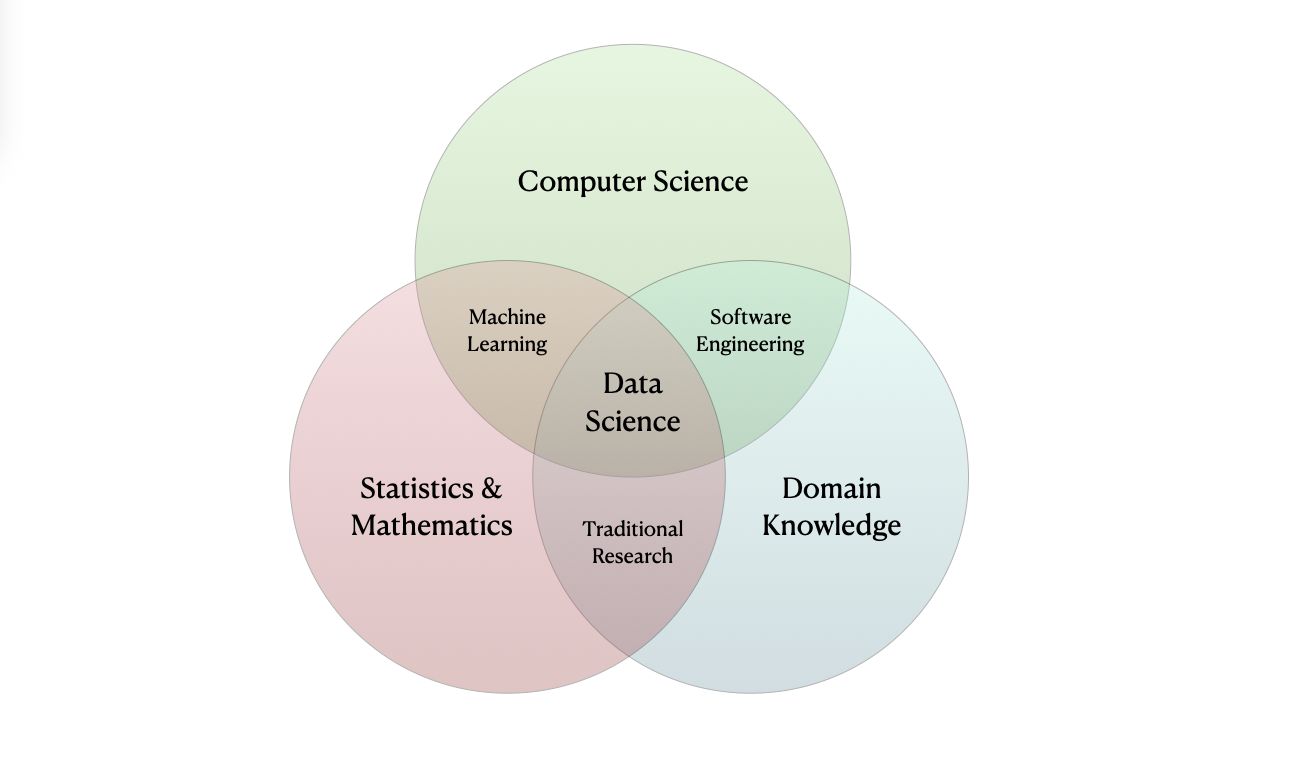
Data Science Venn Diagram.
🔢 Data
What is Data?
Definition: Data
Data is (digital) information (such as measurements or statistics) used as a basis for reasoning, discussion, or calculation.
- Raw data is often difficult or even impossible to interpret.
- Hence, the need for Data Science!

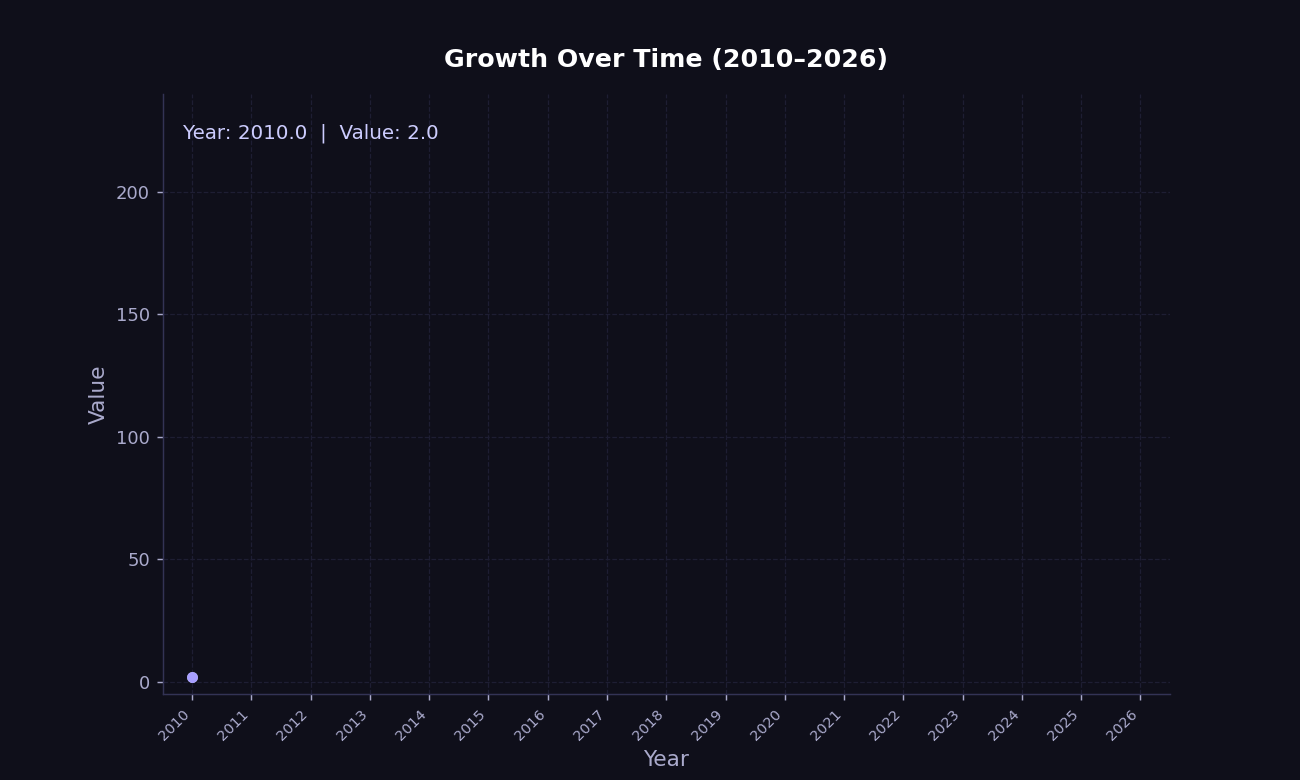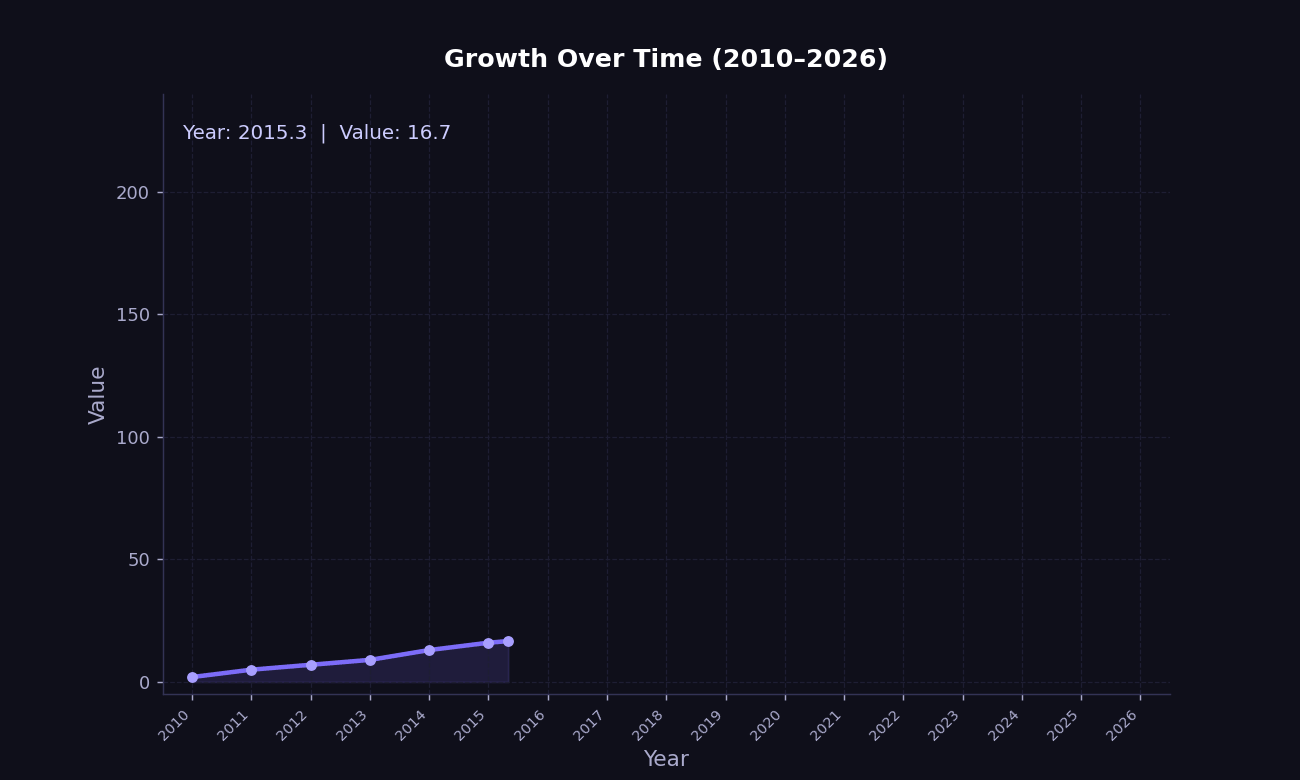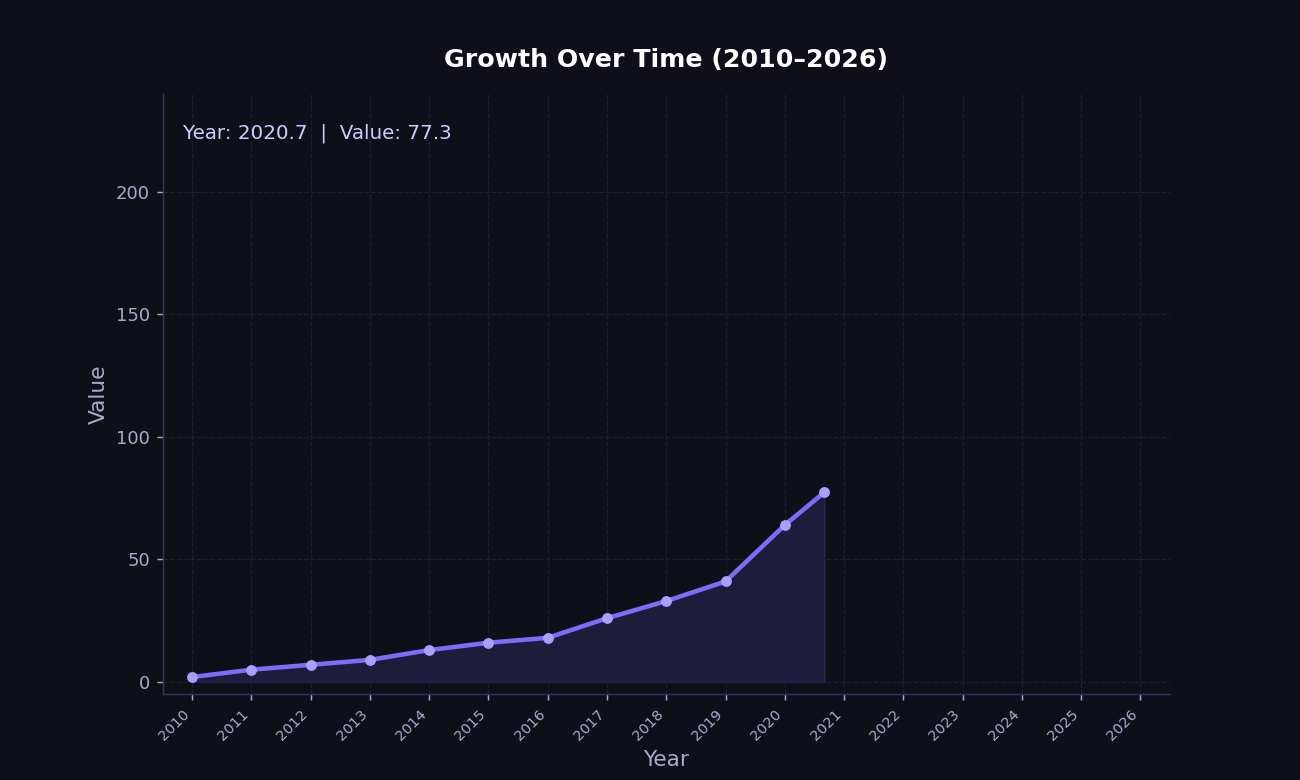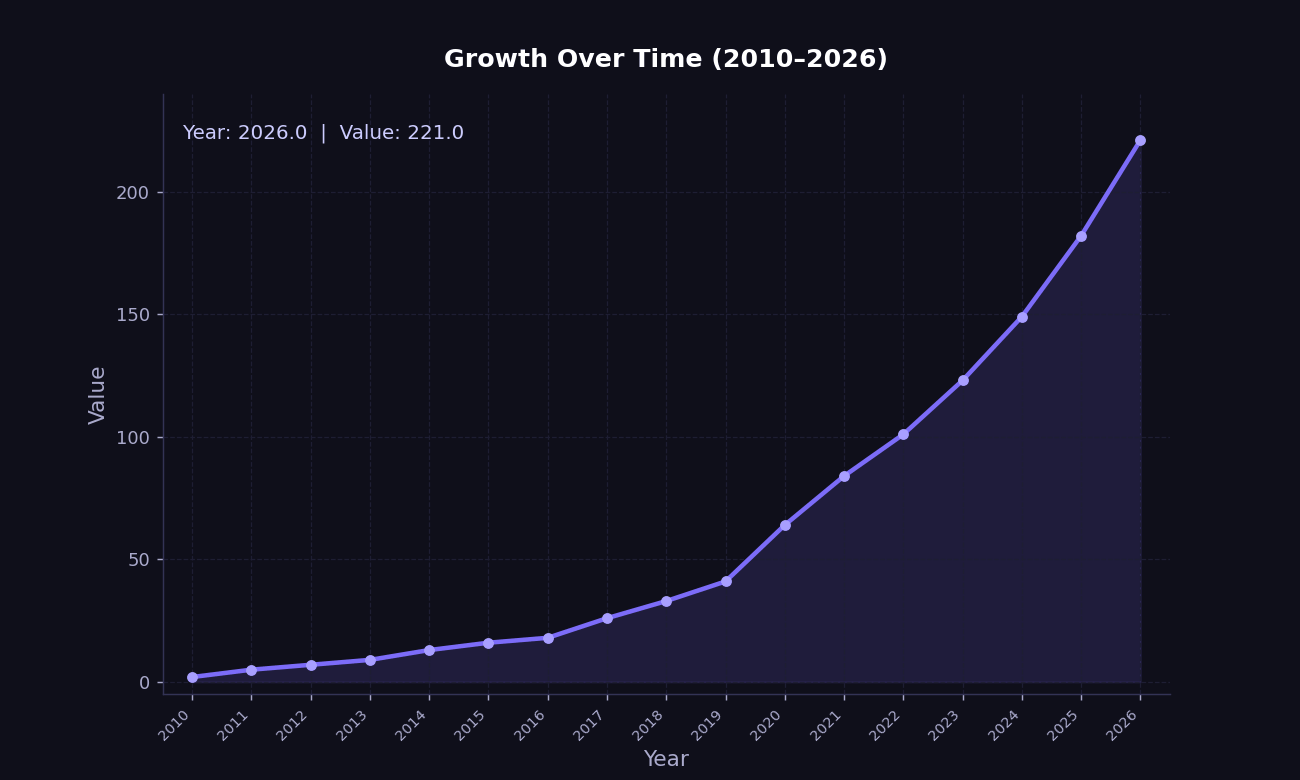
Data Growth
Sooo much data!
The amount of data being collected, stored, and processed is growing exponentially!
Larger variety of increasingly complicated data types.
Semantics vs Structure
What is the difference?
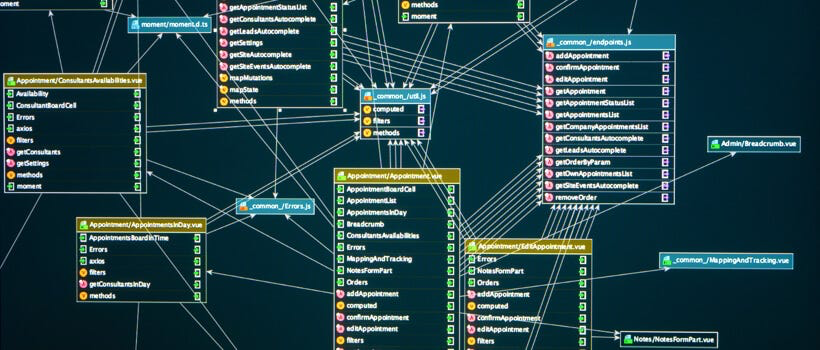
In general, we distinguish between the semantics and structure of a dataset.
The semantics of a dataset refers to the meaning behind the data.
- Interpretation and representation.
The structure of a dataset refers to the way the data is organized.
- Shape, organization and storage.
Data Type Hierarchy
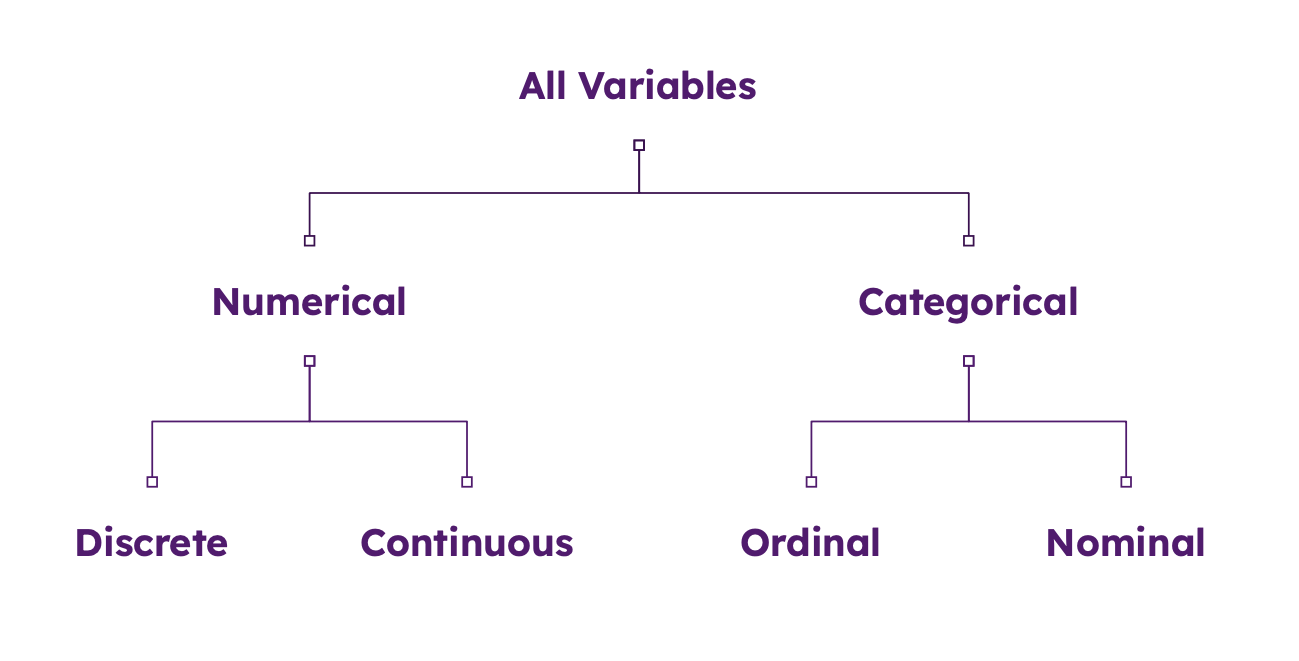
🔢 Tabular Data
- We will primarily be working with tabular data.
- Spreadsheet style datasets containing both quantitative and qualitative data.
- We will occasionally deal with more complex structures such as databases.
Complicated Data Example - MNIST
🖐️ Handwritten Digits
MNIST database, a subset of the larger NIST made available by Yann LeCun on Kaggle.
- The database is of handwritten digits.
- White text on a black background.
- The data is complicated!
- There are 70,000 observations total (60,000 training and 10,000 testing).
- Each observation consists of 28x28 pixels, with a total of 784 pixels per observation.
- Each pixel is a grayscale value between 0 and 255 (0 = black, 255 = white).
Handwritten Digits
🖐️ Handwritten Digits

MNIST Data Visualization.
📖 Data Literacy
My point is…
The world of data is confusing! 😵💫
- Different data types with different formats and different dimensions.
- Each has unique challenges and techniques for data scientists to learn.
- We do not have time to go over everything, but we will cover some of the most important cases!
- It is a long road to build up your data literacy.

Definition: Data Literacy
Data Literacy is the ability to explore, understand, and communicate with data in a meaningful way. (Tableau)
🔄 Data Science Lifecycle
What is the Data Science Lifecycle?
The data science lifecycle (DLS) is the following multi-step process used to extract actionable insights from data:
- ❓ Hypothesize:
- Formulate a question of interest.
- 🧹 Collect and Prepare:
- Sample or acquire data.
- Understand your dataset (origins, limits).
- Clean up and organize your data.
- 📈 Explore and Analyze:
- Explore the data to understand its structure.
- Analyze data relationships.
- 🗣️ Interpret and Communicate:
- Interpret the results of the analysis.
- Communicate your results.

Guidelines
Don’t feel restricted!
- This lifecycle is not necessarily sequential.
- You may start with a data set that needs processing before forming your hypothesis.
- You may need to reformulate your hypothesis as your understanding deepens.
- Think of this as a guide to help structure your approach.
In reality, the data science lifecycle has a more complex structure.

❓ Hypothesize
Deceptively Simple
- Typically we begin with a question we want to answer.
- 💉 Does this new drug improve patient outcomes?
- 🛳️ What impact has increased shipping had on marine mammal populations?
- 🎓 Does this new policy improve student performance?
- The scope of your hypothesis should inform the data you collect.
- Am I considering a specific population?
- Do I wish to generalize?
- Does this data already exist?

🧹 Collect and Prepare
This takes time!
- Design experiment / survey or collect second-hand data.
- There are whole courses dedicated to experimental design.
- ➡️ Our hypothesis informs the data we collect.
- ⬅️ With second-hand data, this is often reversed.
- 🧹 Data preparation is often a time consuming process.
- Errors are challenging to locate.
- Missing data needs to be handled appropriately.
- Formatting and readability issues.

📈 Explore and Analyze
Understanding the data
- Analyze the data to understand its structure.
- Visualizations.
- Descriptive statistics.
- Identify relationships between variables.
- Inferential modelling.
- Hypothesis testing.
- Sometimes we wish to forecast future outcomes.
- Predictive modelling.
- Sometimes we solely focus on model outcomes.
- Model selection and evaluation.
- Machine learning models.

🗣️ Interpret and Communicate
Refer back to your hypothesis
- Interpret our results.
- How do our results fit our hypothesis?
- How significant are our results?
- How do our results compare to other studies?
- Communicate our results.
- Write a report.
- Present your findings.
- Ensure reproducibility.
- Share your code and data.
- Maximize transparency.
- Let’s look at an example…
DSL Example - Visualize
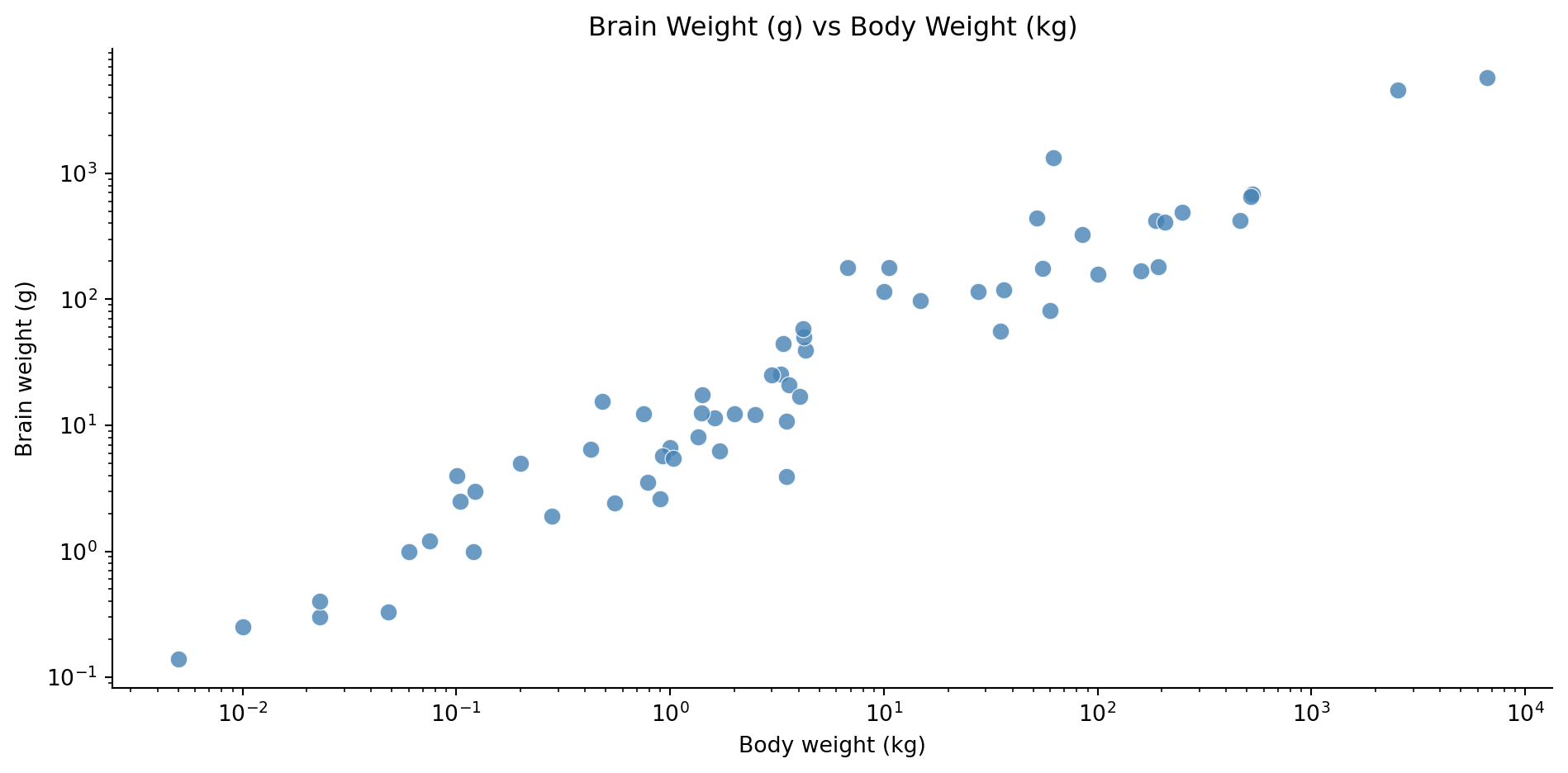
- There is a clear linear relationship between the variables on the log scale.
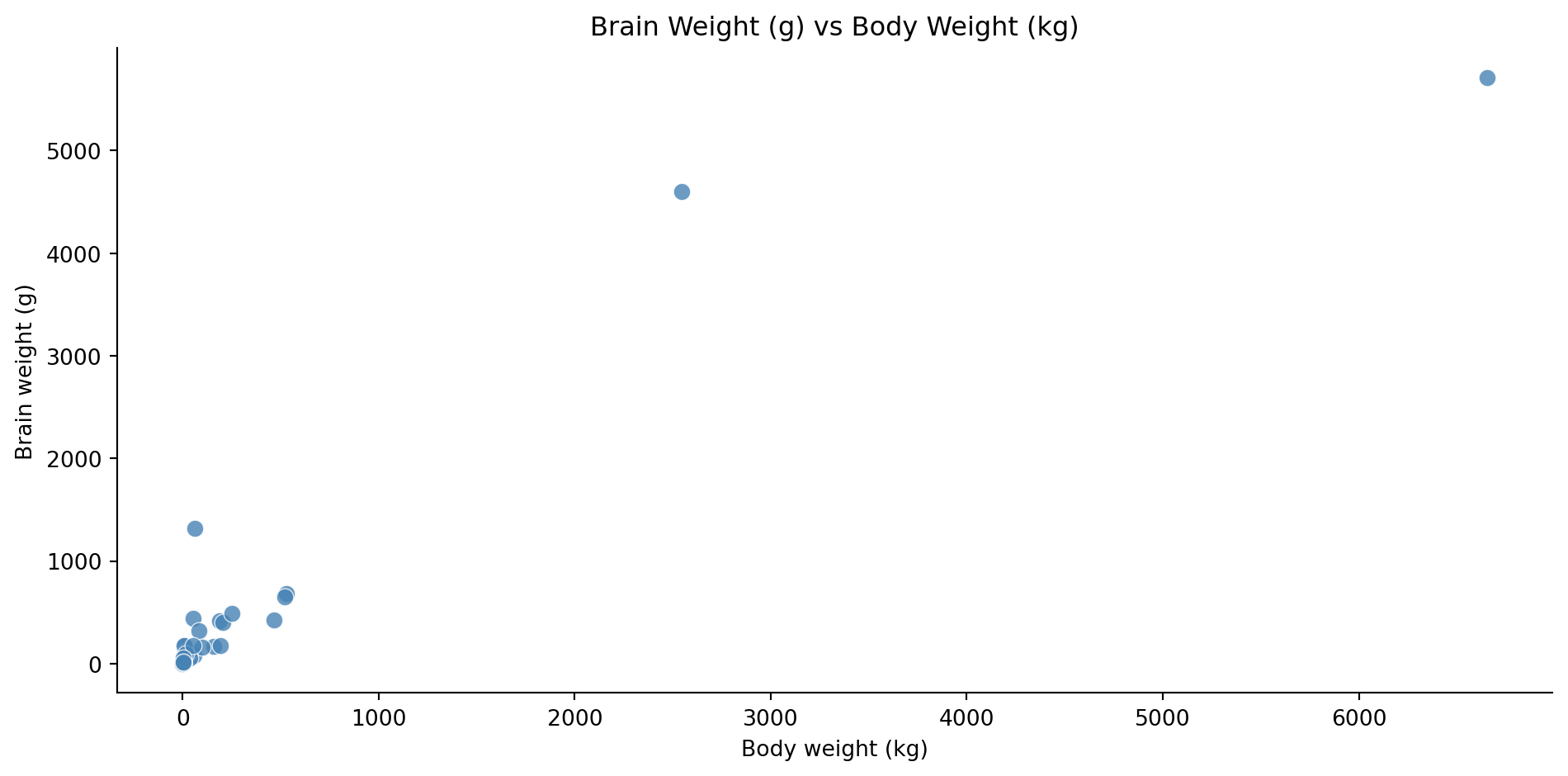
- The plot shows a positive relationship between the variables.
- To better see the relationship, we can use log-log axes.